SVN莫名奇妙的错误
就改了个路径,莫名奇妙的各种问题都出来了,什么锁定啊,树冲突啊,更新提示说没有更新的文件,提交显示目录不存在或者冲突之类的,实在很无语。后来想到了个猥琐的方法,如下:
把要提交的svn目录下,搜索出.svn文件,然后把这些文件干掉,再提交就可以了。
组合模式
总结关于组合模式的目的:
客户程序可以向处理简单元素一样来处理复杂元素。
关于组合模式的作用:
可用于处理对象的部分-整体结构,经常用于处理拥有树状结构的问题。
对应的类图:
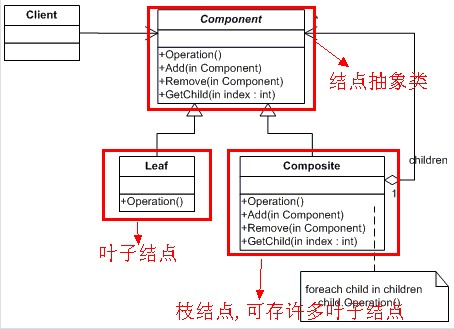
下列贴一段代码来说明应用组合模式+迭代器来模拟对树的遍历,顺便复习了数据结构中的树相关知识。本代码参考网上相关代码:
/**
* 结点接口
* @author ChenST
*/
public interface Node {
/**
* 添加结点
* @param node
*/
public void add(Node node);
/**
* 获取一个迭代器
* @return
*/
public Iterator<Node> iterator();
}
/**
* 抽象结点,主要实现toString方法,可用于识别各个结点
* @author ChenST
*
*/
public abstract class AbstractNode implements Node{
/** 结点名字 */
protected String nodeName;
public AbstractNode(String nodeName){
this.nodeName = nodeName;
}
public String toString(){
return nodeName;
}
}
/**
* 叶子结点,不允许有子结点
* @author ChenST
*/
public class LeafNode extends AbstractNode {
public LeafNode(String nodeName) {
super(nodeName);
}
@Override
public void add(Node node) {
throw new UnsupportedOperationException("叶子结点不能添加结点");
}
@Override
public Iterator<Node> iterator() {
//返回空的迭代器,永远无法进行迭代
return new NullIterator<Node>();
}
}
/**
* 枝结点,可存储多数叶子结点
* @author ChenST
*/
public class BranchNode extends AbstractNode {
//树枝结点下的所有孩子结点
private List<Node> childs = new ArrayList<Node>();
public BranchNode(String nodeName) {
super(nodeName);
}
@Override
public void add(Node node) {
childs.add(node);
}
@Override
public Iterator<Node> iterator() {
return childs.iterator();
}
}
/**
* 空的迭代器
* @author ChenST
*
* @param <T>
*/
public class NullIterator<T> implements Iterator<T> {
@Override
public boolean hasNext() {
//永远没有下一个结点
return false;
}
@Override
public T next() {
//永远为空
return null;
}
@Override
public void remove() {
//没有移除方法
}
}
/**
* 深度优先迭代器
* @author ChenST
*/
public class DepthFirstIterrator implements Iterator<Node> {
//堆栈
private Stack<Iterator<Node>> stack = new Stack<Iterator<Node>>();
public DepthFirstIterrator(Iterator<Node> iter){
this.stack.push(iter);
}
@Override
public boolean hasNext() {
if(stack.isEmpty()){
return false;
}else{
Iterator<Node> iter = this.stack.peek();
if(iter.hasNext()){
return true;
}else{
this.stack.pop();
return hasNext();
}
}
}
@Override
public Node next() {
if(hasNext()){
Iterator<Node> iter = this.stack.peek();
Node node = iter.next();
if(node instanceof BranchNode){
this.stack.push(node.iterator());
}
return node;
}
return null;
}
@Override
public void remove() {
throw new UnsupportedOperationException("不支持移除操作");
}
}
/**
* 广度优先算法的迭代器
* @author ChenST
*/
public class BreadthFirstIterator implements Iterator<Node> {
//存储临时结点操作的队列
private Queue<Iterator<Node>> queue = new LinkedList<Iterator<Node>>();
public BreadthFirstIterator(Iterator<Node> iter){
queue.offer(iter);
}
@Override
public boolean hasNext() {
if(queue.isEmpty()){
return false;
}else{
Iterator<Node> iter = queue.peek();
if(iter.hasNext()){
return true;
}else{
queue.poll();
return hasNext();
}
}
}
@Override
public Node next() {
if (hasNext()) {
Iterator<Node> it = queue.peek();
Node node = it.next();
if(node instanceof BranchNode){
queue.offer(node.iterator());
}
return node;
}
return null;
}
@Override
public void remove() {
throw new UnsupportedOperationException("不支持移除操作");
}
}
public class Test {
public static void main(String[] args) {
//构建树
Node A = new BranchNode("A");
Node B = new BranchNode("B");
Node C = new BranchNode("C");
Node D = new BranchNode("D");
Node E = new LeafNode("E");
Node F = new LeafNode("F");
Node G = new LeafNode("G");
Node K = new LeafNode("K");
A.add(B);
A.add(C);
B.add(D);
B.add(E);
C.add(F);
D.add(G);
D.add(K);
//深度优先迭代器
System.out.print("深度优先迭代器:"+A);
Iterator<Node> iterDepth = new DepthFirstIterrator(A.iterator());
while(iterDepth.hasNext()){
System.out.print(iterDepth.next());
}
//广度优先迭代器
Iterator<Node> iterBreadth = new BreadthFirstIterator(A.iterator());
System.out.print("\n广度优先迭代器:"+A);
while(iterBreadth.hasNext()){
System.out.print(iterBreadth.next());
}
}
}
深度优先迭代器:ABDGKECF 广度优先迭代器:ABCDEFGK
本例子利用自定义迭代器(深度优先迭代器和广度优先迭代器)对构建的树进行了访问。可以看到利用组合模式不管对叶子结点访问还是对整颗树进行访问或者对树的某个子树进行访问都是用同样的方法都可以达到目的。这就是组合模式的核心。
桥接模式
关于桥接模式的定义:
将抽象与行为相分离,使得他们各自可以独立变化,然后可通过动态组合得到想要的结果,目标是实现解耦。桥接模式的类关系图如下:
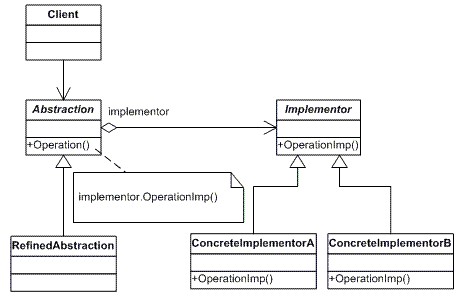
现在举一个例子来说明桥接模式.
以最常用的咖啡问题来说明。现在模拟的场景是这样子的:
| 咖啡有分大杯和中杯,同时咖啡里面可以选择加牛奶,也可以选择加苹果汁,也可以什么都不加。因为刚开张,所以目前就只有大杯和中杯,未来可能会有更多规格的杯子,同时也会有更多的调料给客人选择,设计一个具有弹性的程序 |
分析:按照目前的情况,最简单的做法就是分别写出6种类,来表示六种不同组合的咖啡。
我们可以分析到这种做法虽然和直观,但是会存在很多问题,其中之一就是这6个类的每一个类都已经具体的代表了一种咖啡,换句话说,这几个类是没办法复用的,这当然是我们不想要的,另外一个问题就是,如果添加一个规格的杯子,比如小杯,又要再写小杯中分别加不同调料的类,可想而知,后面店的规模大起来的话,会造成类的“炸弹”。
我们想要的结果是,当增加一种调料时只需要增加一个类,增加一个杯子规模的时候也只需要增加一个类就可以达到目的,这就需要用到桥接模式了。
桥接模式分析法:把属性和行为分别抽象并独立开来,行为就是加牛奶加苹果汁等,属性就是大杯中杯之类的。我们的目的就是把行为和属性完全没有耦合,通过组合来形成不同的咖啡,通俗点说,例如我们只提供的各种零件,让使用者去使用而已,不提供整合好的东西。
请看分析的类图:
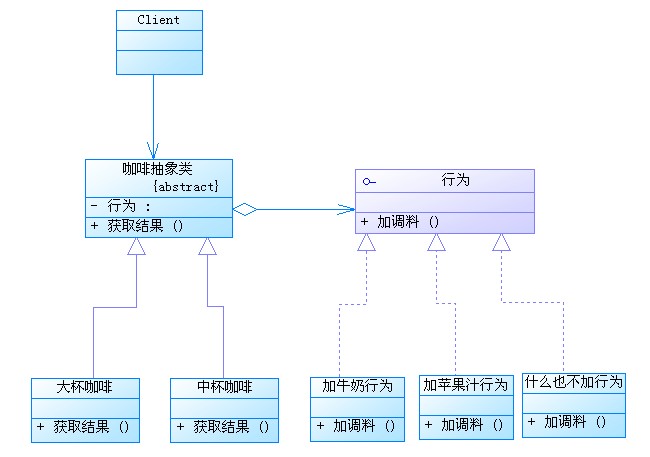
具体来看看代码的实现:
/**
* 咖啡的行为
* @author ChenST
*
*/
public interface Action {
/**
* 做事情
* @return
*/
public String doThing();
}
/**
* 加牛奶的行为
* @author ChenST
*/
public class AddMilkAction implements Action {
@Override
public String doThing() {
return "加了[牛奶]";
}
}
/**
* 什么也不加的行为
* @author ChenST
*/
public class EmptyAction implements Action {
@Override
public String doThing() {
return "什么也没加";
}
}
/**
* 加了苹果汁
* @author ChenST
*
*/
public class AddAppleAction implements Action {
@Override
public String doThing() {
return "加了[苹果汁]";
}
}
/**
* 咖啡抽象类
* @author ChenST
*/
public abstract class Coffee {
private Action action;
public Coffee(Action action){
this.action = action;
System.out.println(this.result());
}
public Action getAction(){
return action;
}
/**
* 得到的咖啡结果
* @return
*/
public abstract String result();
}
/**
* 大杯咖啡
* @author ChenST
*/
public class BigCupCoffe extends Coffee {
public BigCupCoffe(Action action){
super(action);
}
@Override
public String result() {
String thing = this.getAction().doThing();
return "[大杯]"+thing+"的咖啡";
}
}
/**
* 中杯咖啡
* @author ChenST
*
*/
public class MiddleCupCoffee extends Coffee {
public MiddleCupCoffee(Action action){
super(action);
}
@Override
public String result() {
String thing = this.getAction().doThing();
return "[中杯]"+thing+"的咖啡";
}
}
public class Test {
public static void main(String[] args) {
//加牛奶的大杯咖啡
Coffee coffee1 = new BigCupCoffe(new AddMilkAction());
//什么也没加的大杯咖啡
Coffee coffee2 = new BigCupCoffe(new EmptyAction());
//加苹果汁的大杯咖啡
Coffee coffee3 = new BigCupCoffe(new AddAppleAction());
//加牛奶的中杯咖啡
Coffee coffee4 = new MiddleCupCoffee(new AddMilkAction());
//什么也没加的中杯咖啡
Coffee coffee5 = new MiddleCupCoffee(new EmptyAction());
//加苹果汁的中杯咖啡
Coffee coffee6 = new MiddleCupCoffee(new AddAppleAction());
}
}
[大杯]加了[牛奶]的咖啡 [大杯]什么也没加的咖啡 [大杯]加了[苹果汁]的咖啡 [中杯]加了[牛奶]的咖啡 [中杯]什么也没加的咖啡 [中杯]加了[苹果汁]的咖啡
代理模式-静态代理
相对于动态代理,静态代理好理解多了。
看静态代理涉及的角色以及相关关系图
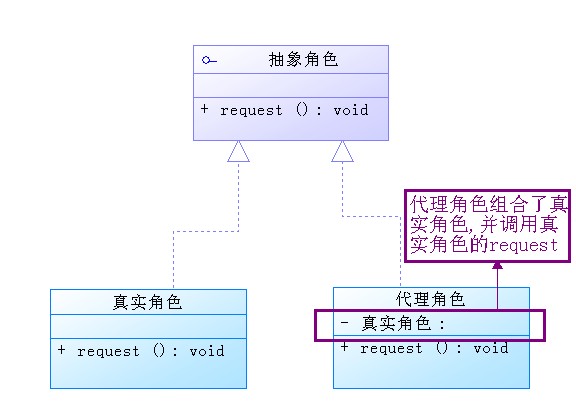
再来看看代码实现,(相关知识写在代码注释中了~呵~)
//抽象对象
public interface ISubject {
public void request();
}
//真实对象,实现类
public class SubjectImpl implements ISubject{
@Override
public void request() {
System.out.println("hello world");
}
}
//代理对象 ,代理对象和实际对象都实现了抽象对象
//这样的好处,可以用代理对象来完成相应的操作,
//也可以用实际对象来完成操作
//某些情况,就是不想通过实际对象去完成操作,
//要交给代理对象去完成相应的操作.
public class SubjectProxy implements ISubject {
//组合真实对象
private ISubject subject = new SubjectImpl();
@Override
public void request() {
//在执行实际对象的request之前,还可以做一些其他操作
//是不是很像Spring 中的AOP啊
//--------------------------
//实际上是调用真实对象的request
//只是这是代理对象帮忙去调用reqeust
//很符合实际中的代理意义
subject.request();
//--------------------------
//还可以在实际对象操作结束之后,做一些其他操作
}
}
public class Test {
public static void main(String[] args) {
ISubject proxy = new SubjectProxy();
proxy.request();
}
}
完成,可以看到静态代理和动态代理的区别,静态代理,一个真实对象对应一个代理,如果有很多个真实对象需要代理,那么就需要很多个代理对象了,而动态代理的作用就在于此,他有一个总代理,可由代理工厂根据进入的代理类来得到代理对象。
呵呵~~
Spring事务属性说明
Spring事务属性配置属性说明如下:
|
PROPAGATION_REQUIRED 【支持当前事务,如果当前没有事务,就新建一个事务。(常用)】 PROPAGATION_SUPPORTS 【支持当前事务,如果当前没有事务,就以非事务方式执行】 PROPAGATION_MANDATORY 【支持当前事务,如果当前没有事务,就抛出异常】 PROPAGATION_REQUIRES_NEW 【新建事务,如果当前存在事务,把当前事务挂起】 PROPAGATION_NOT_SUPPORTED 【以非事务方式执行操作,如果当前存在事务,就把当前事务挂起】 PROPAGATION_NEVER 【以非事务方式执行,如果当前存在事务,则抛出异常】 PROPAGATION_NESTED 【如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则进行与PROPAGATION_REQUIRED类似的操作】 -Exception表示有Exception抛出时,事务回滚。-代表回滚+就代表提交 readonly 就是read only, 设置操作权限为只读,一般用于查询的方法,优化作用 |
No identifier specified for entity错误原因
昨日,做Hibernate OR 映射,启动单元测试~忽现错误:
org.hibernate.AnnotationException: No identifier specified for entity
百度得解:
数据库表中没有建主健或者复合主键。后而建立复合主键,问题消失。
代理模式-动态代理
最近项目中一直在配置Spring AOP,听说AOP是基于动态代理模式实现的,于是乎就去学习了动态代理,虽然还是迷迷糊糊,不过还是将自己的学习成功总结下。
自己写了个例子来说明:(部分说明写在代码中)
//汽车类
public class Car {
//牌子
private String brand;
public Car(String brand){
this.brand = brand;
}
//获取汽车的描述
public String getDescribe(){
return brand+"车";
}
}
//奥迪车
public class AudiCar extends Car{
public AudiCar(){
super("奥迪");
}
}
//奔驰车
public class BenzCar extends Car {
public BenzCar(){
super("奔驰");
}
}
//汽车代理接口
public interface CarProxy {
public void sellCar(Car car);
}
//汽车代理实现类
public class CarProxyImpl implements CarProxy {
@Override
public void sellCar(Car car){
System.out.println("卖出一辆"+car.getDescribe());
}
}
//动态代理对象(调用处理器)-可代理任何的代理对象
//这个类是被java.lang.reflect.Proxy所调用
public class DynamicProxy implements InvocationHandler{
//代理对象
private Object proxyObject;
public DynamicProxy(Object proxyObject){
this.proxyObject = proxyObject;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
//方法执行前做事 Spring AOP 切面的原理 ,对方法method进行横切
//在真正执行方法之前或者之后做一些额外的操作
//就这就Spring AOP实现横向切面的原理了
System.out.println("打算执行方法");
Object object = method.invoke(proxyObject, args);
//方法执行之后做的事,Spring AOP 切面的原理
System.out.println("方法执行之后");
return object;
}
}
//代理工厂
public class ProxyFactory {
// 创建一个代理
public static Object createProxy(Object proxyObject) { // 被代理的对象
Class<? extends Object> clazz = proxyObject.getClass();
Object proxy = Proxy.newProxyInstance(clazz.getClassLoader(), clazz
.getInterfaces(), new DynamicProxy(proxyObject));
return proxy;
}
}
//测试类
public class Test {
public static void main(String[] args) {
//通过代理工厂创建一个汽车代理
CarProxy carProxy = (CarProxy) ProxyFactory
.createProxy(new CarProxyImpl());
carProxy.sellCar(new AudiCar());
carProxy.sellCar(new BenzCar());
}
}
打算执行方法 卖出一辆奥迪车 方法执行之后 打算执行方法 卖出一辆奔驰车 方法执行之后
动态代理的好处就是可以代理任意的代理对象,都可以通过代理工厂中指定代理对象即可。
另外就是可对执行方法加入一些额外操作,就是AOP了,只是Spring把这些都通过配置来实现。
Oracle 横表和纵表
前一段时间了解到的,今天有空写下,备忘~
先来说说横表和纵坐表的概念,先来看看以下两图:

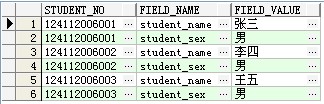
第一张图就是横表,一行表示了一个实体记录,这就是我们传统的设计表的形式
第二张图就是纵表,他的一行记录,是用于表示某个学生的属性名和属性值对应关系,像这边有两个属性(名字和性别),在纵表中就要用两条记录来表示一个学生。
从上面可以观察出,横表的好处是清晰可见,一目了然,但是有一个弊端,如果现在要把这个表加一个字段,那么就必须重建表结构。对于这种情况,在纵表中只需要添加一条记录,就可以添加一个字段,所消耗的代价远比横表小,但是纵表的对于数据描述不是很清晰,而且会造成数据库数量很多,两者利弊在于此。所以,应该把不容易改动表结构的设计成横表,把容易经常改动不确定的表结构设计成纵表。
在实际开发中,经常需要互相转换横表和纵表的形式,这里贴个从纵表数据转成横表显示的形式。
Select student_no,
max(decode(field_name,'student_name',field_value)) As student_name,
max(decode(field_name,'student_sex',field_value )) As student_sex
From cuc_student_y Group By student_no;
横转纵暂时不知~~望高人指点~~
Spring AOP 之 RegexpMethodPointcutAdvisor
昨天,做了有关日志的AOP,对相关的AOP知识总结如下:
1.引入AOP(Aspect Oroented Programming) 面向切面编程,是消除代码重复的一种方法。
2.Spring AOP 中提供了两种PointcutAdvisor,分别是:
①org.springframework.aop.support.RegexpMethodPointcutAdvisor (需要加上完整类名,可以用Spring提供的匹配方式)
②org.springframework.aop.support.NameMatchMethodPointcutAdvisor(只需要方法名,不用加类名)
今天,主要来说明下RegexpMethodPointcutAdvisor的用法。贴一个例子来说明,一些说明都写在注释中~看贴的代码:
/**
* 打印接口
* @author ChenST
*/
public interface IPrinter {
/** 打印接口 */
public void print();
}
/**
* 打印接口实现类
* @author ChenST
*/
@Repository
public class PrinterImpl implements IPrinter{
@Override
public void print() {
System.out.println("hello world");
}
}
/**
* 通知,在执行方法执行后调用该方法
* @author ChenST
*/
//对应的还有MethodBeforeAdvice等
public class AfterPrinter implements AfterReturningAdvice{
//第一个参数表示 切入方法的 [返回对象]
//第二个参数表示 切入方法的 [方法反射对象]
//第三个参数表示 切入方法的 [参数数组(方法的所有参数组成)]
//第四个参数表示 [调用该方法的对象]
@Override
public void afterReturning(Object returnObject, Method method,
Object[] argArray, Object callObject) throws Throwable {
System.out.println("add log:print Hello world");
}
}
<context:annotation-config />
<context:component-scan base-package="com.shine" />
<bean id="printer" class="com.shine.PrinterImpl"/>
<bean id="afterPrinter" class="com.shine.AfterPrinter"/>
<!-- 配置一个拦截器 (切入点对象,确定何时何地调用拦截器) -->
<bean id="pointcutAdvisor" class="org.springframework.aop.support.RegexpMethodPointcutAdvisor">
<!-- [通知,特定连接点所采取的动作] -->
<!-- 加入切面,切面为当执行完print方法后 再执行加入的切面 -->
<property name="advice">
<ref local="afterPrinter"/>
</property>
<!-- 要拦截的方法,可根据Spring提供匹配方式进行拦截 -->
<property name="pattern">
<!-- .表示符合任何单一字元
### +表示符合前一个字元一次或多次
### *表示符合前一个字元零次或多次
### \Escape任何Regular expression使用到的符号
-->
<!-- .*表示前面的前缀(包括包名) 表示print方法-->
<value>.*print</value>
</property>
</bean>
<!-- ### 代理工程 -->
<bean id="proxyFactory" class="org.springframework.aop.framework.ProxyFactoryBean">
<!-- 指定目标对象,目标对象是PrinterImpl对象 -->
<property name="target">
<ref local="printer"/>
</property>
<!-- 该目标中加入拦截器pointcutAdvisor -->
<property name="interceptorNames">
<list>
<value>pointcutAdvisor</value>
</list>
</property>
</bean>
/**
* 测试类
*/
public class TestMain {
public static void main(String[] args) {
ApplicationContext ctx = new FileSystemXmlApplicationContext(
"classpath:applicationContext.xml");
// ☆注意:这里的Bean对象获取必须从代理工厂中去取,否则无法切入
IPrinter printer = (IPrinter) ctx.getBean("proxyFactory");
printer.print();
}
}
hello world add log:print Hello world
感觉这么多开源东西中,最需要研究的就是Spring了~~ = =|| 继续study~~
一道英文数学题
昨天下午,接到蒜头发的一道题目,结果下午都没在工作,一直在算这道题目,本人对数学感兴趣,没算出来总觉得怪怪的。
题目如下:
|
C L O V E R + C R O C U S ----------------------- V I O L E T 这道英语算式译成中文就是“三叶草+番红花=紫罗兰”。如果算式是正确的,那么每个字母应该各代表什么数字?注意:相同的字母表示同一数字,不同字母表示不同数字。 |
本来想用程序实现下,结果发现按照穷举法要执行 1010 次,于是就想根据一些条件排除一些数字,来减少执行次数,但是排着排着,手动就解出来了。
用的是排除法,假设10个字母都有10种可能(0-9),解题过程(排除过程如下)
|
//1.C.V!=0 |
最终得出结果:
|
C={2}; L={8}; O={0}; V={5}; E={1}; R={6}; S={7}; U={9}; I={4}; T={3}; |
结果验证:
|
280516 |
正确。