No identifier specified for entity错误原因
昨日,做Hibernate OR 映射,启动单元测试~忽现错误:
org.hibernate.AnnotationException: No identifier specified for entity
百度得解:
数据库表中没有建主健或者复合主键。后而建立复合主键,问题消失。
代理模式-动态代理
最近项目中一直在配置Spring AOP,听说AOP是基于动态代理模式实现的,于是乎就去学习了动态代理,虽然还是迷迷糊糊,不过还是将自己的学习成功总结下。
自己写了个例子来说明:(部分说明写在代码中)
//汽车类
public class Car {
//牌子
private String brand;
public Car(String brand){
this.brand = brand;
}
//获取汽车的描述
public String getDescribe(){
return brand+"车";
}
}
//奥迪车
public class AudiCar extends Car{
public AudiCar(){
super("奥迪");
}
}
//奔驰车
public class BenzCar extends Car {
public BenzCar(){
super("奔驰");
}
}
//汽车代理接口
public interface CarProxy {
public void sellCar(Car car);
}
//汽车代理实现类
public class CarProxyImpl implements CarProxy {
@Override
public void sellCar(Car car){
System.out.println("卖出一辆"+car.getDescribe());
}
}
//动态代理对象(调用处理器)-可代理任何的代理对象
//这个类是被java.lang.reflect.Proxy所调用
public class DynamicProxy implements InvocationHandler{
//代理对象
private Object proxyObject;
public DynamicProxy(Object proxyObject){
this.proxyObject = proxyObject;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
//方法执行前做事 Spring AOP 切面的原理 ,对方法method进行横切
//在真正执行方法之前或者之后做一些额外的操作
//就这就Spring AOP实现横向切面的原理了
System.out.println("打算执行方法");
Object object = method.invoke(proxyObject, args);
//方法执行之后做的事,Spring AOP 切面的原理
System.out.println("方法执行之后");
return object;
}
}
//代理工厂
public class ProxyFactory {
// 创建一个代理
public static Object createProxy(Object proxyObject) { // 被代理的对象
Class<? extends Object> clazz = proxyObject.getClass();
Object proxy = Proxy.newProxyInstance(clazz.getClassLoader(), clazz
.getInterfaces(), new DynamicProxy(proxyObject));
return proxy;
}
}
//测试类
public class Test {
public static void main(String[] args) {
//通过代理工厂创建一个汽车代理
CarProxy carProxy = (CarProxy) ProxyFactory
.createProxy(new CarProxyImpl());
carProxy.sellCar(new AudiCar());
carProxy.sellCar(new BenzCar());
}
}
打算执行方法 卖出一辆奥迪车 方法执行之后 打算执行方法 卖出一辆奔驰车 方法执行之后
动态代理的好处就是可以代理任意的代理对象,都可以通过代理工厂中指定代理对象即可。
另外就是可对执行方法加入一些额外操作,就是AOP了,只是Spring把这些都通过配置来实现。
Oracle 横表和纵表
前一段时间了解到的,今天有空写下,备忘~
先来说说横表和纵坐表的概念,先来看看以下两图:

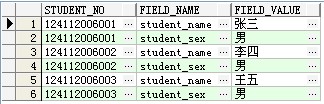
第一张图就是横表,一行表示了一个实体记录,这就是我们传统的设计表的形式
第二张图就是纵表,他的一行记录,是用于表示某个学生的属性名和属性值对应关系,像这边有两个属性(名字和性别),在纵表中就要用两条记录来表示一个学生。
从上面可以观察出,横表的好处是清晰可见,一目了然,但是有一个弊端,如果现在要把这个表加一个字段,那么就必须重建表结构。对于这种情况,在纵表中只需要添加一条记录,就可以添加一个字段,所消耗的代价远比横表小,但是纵表的对于数据描述不是很清晰,而且会造成数据库数量很多,两者利弊在于此。所以,应该把不容易改动表结构的设计成横表,把容易经常改动不确定的表结构设计成纵表。
在实际开发中,经常需要互相转换横表和纵表的形式,这里贴个从纵表数据转成横表显示的形式。
Select student_no,
max(decode(field_name,'student_name',field_value)) As student_name,
max(decode(field_name,'student_sex',field_value )) As student_sex
From cuc_student_y Group By student_no;
横转纵暂时不知~~望高人指点~~
Spring AOP 之 RegexpMethodPointcutAdvisor
昨天,做了有关日志的AOP,对相关的AOP知识总结如下:
1.引入AOP(Aspect Oroented Programming) 面向切面编程,是消除代码重复的一种方法。
2.Spring AOP 中提供了两种PointcutAdvisor,分别是:
①org.springframework.aop.support.RegexpMethodPointcutAdvisor (需要加上完整类名,可以用Spring提供的匹配方式)
②org.springframework.aop.support.NameMatchMethodPointcutAdvisor(只需要方法名,不用加类名)
今天,主要来说明下RegexpMethodPointcutAdvisor的用法。贴一个例子来说明,一些说明都写在注释中~看贴的代码:
/**
* 打印接口
* @author ChenST
*/
public interface IPrinter {
/** 打印接口 */
public void print();
}
/**
* 打印接口实现类
* @author ChenST
*/
@Repository
public class PrinterImpl implements IPrinter{
@Override
public void print() {
System.out.println("hello world");
}
}
/**
* 通知,在执行方法执行后调用该方法
* @author ChenST
*/
//对应的还有MethodBeforeAdvice等
public class AfterPrinter implements AfterReturningAdvice{
//第一个参数表示 切入方法的 [返回对象]
//第二个参数表示 切入方法的 [方法反射对象]
//第三个参数表示 切入方法的 [参数数组(方法的所有参数组成)]
//第四个参数表示 [调用该方法的对象]
@Override
public void afterReturning(Object returnObject, Method method,
Object[] argArray, Object callObject) throws Throwable {
System.out.println("add log:print Hello world");
}
}
<context:annotation-config />
<context:component-scan base-package="com.shine" />
<bean id="printer" class="com.shine.PrinterImpl"/>
<bean id="afterPrinter" class="com.shine.AfterPrinter"/>
<!-- 配置一个拦截器 (切入点对象,确定何时何地调用拦截器) -->
<bean id="pointcutAdvisor" class="org.springframework.aop.support.RegexpMethodPointcutAdvisor">
<!-- [通知,特定连接点所采取的动作] -->
<!-- 加入切面,切面为当执行完print方法后 再执行加入的切面 -->
<property name="advice">
<ref local="afterPrinter"/>
</property>
<!-- 要拦截的方法,可根据Spring提供匹配方式进行拦截 -->
<property name="pattern">
<!-- .表示符合任何单一字元
### +表示符合前一个字元一次或多次
### *表示符合前一个字元零次或多次
### \Escape任何Regular expression使用到的符号
-->
<!-- .*表示前面的前缀(包括包名) 表示print方法-->
<value>.*print</value>
</property>
</bean>
<!-- ### 代理工程 -->
<bean id="proxyFactory" class="org.springframework.aop.framework.ProxyFactoryBean">
<!-- 指定目标对象,目标对象是PrinterImpl对象 -->
<property name="target">
<ref local="printer"/>
</property>
<!-- 该目标中加入拦截器pointcutAdvisor -->
<property name="interceptorNames">
<list>
<value>pointcutAdvisor</value>
</list>
</property>
</bean>
/**
* 测试类
*/
public class TestMain {
public static void main(String[] args) {
ApplicationContext ctx = new FileSystemXmlApplicationContext(
"classpath:applicationContext.xml");
// ☆注意:这里的Bean对象获取必须从代理工厂中去取,否则无法切入
IPrinter printer = (IPrinter) ctx.getBean("proxyFactory");
printer.print();
}
}
hello world add log:print Hello world
感觉这么多开源东西中,最需要研究的就是Spring了~~ = =|| 继续study~~
一道英文数学题
昨天下午,接到蒜头发的一道题目,结果下午都没在工作,一直在算这道题目,本人对数学感兴趣,没算出来总觉得怪怪的。
题目如下:
|
C L O V E R + C R O C U S ----------------------- V I O L E T 这道英语算式译成中文就是“三叶草+番红花=紫罗兰”。如果算式是正确的,那么每个字母应该各代表什么数字?注意:相同的字母表示同一数字,不同字母表示不同数字。 |
本来想用程序实现下,结果发现按照穷举法要执行 1010 次,于是就想根据一些条件排除一些数字,来减少执行次数,但是排着排着,手动就解出来了。
用的是排除法,假设10个字母都有10种可能(0-9),解题过程(排除过程如下)
|
//1.C.V!=0 |
最终得出结果:
|
C={2}; L={8}; O={0}; V={5}; E={1}; R={6}; S={7}; U={9}; I={4}; T={3}; |
结果验证:
|
280516 |
正确。
Oracle 树状查询
在实际应用中,经常利用数据库保存树状结构的数据,通常用一张表中的两个字段表示,一个是自身的ID,一个是保存父类的ID。在这样具有这种关系中的数据,要求查出的数据具有我们想要的树状显示。这里需要引入Oracle的一个查询语句。
Select * from tablename start with [condition1] Connect By Prior [condition2] where [condition3]
condition1 通常是用于筛选某颗树或者多颗树的结点,这里所的树包括子树,
condtion2 通常是用于连接父结点和子结点的关系,prior 所表示的是上一条记录,通常用法:prior id = pid,(上一条的的ID号是本条记录的父类ID号)这样就把整个树状结构给建立起来了。
conditon3 就是我们通常的where语句,过滤某些记录。
现在看下具体例子。
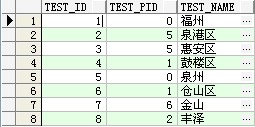
其中Test_ID 表示本身的ID,Test_PID表示父类的ID
这边记录的描述成树状结构就是如下:
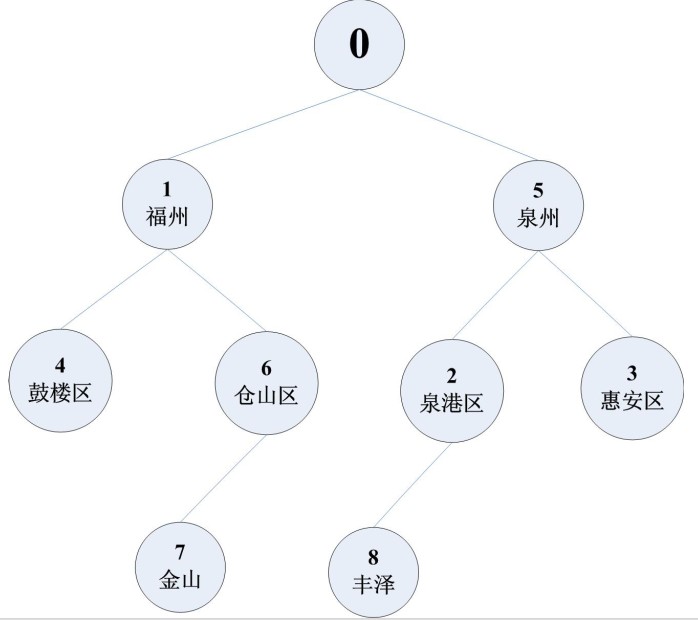
现在,假设我们查询的福州以及福州下的所有子东西,就可以这样查询,
只要取福州的根结点就可以,福州的根结点翻译成数据库中存的数据就是 test_id =1
因此得到的sql如下:
Select * From Test_ t Start With Test_Id = 1 Connect By Prior Test_Id = Test_Pid
查询结果:
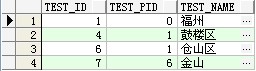
用结构图表示就是如下信息:
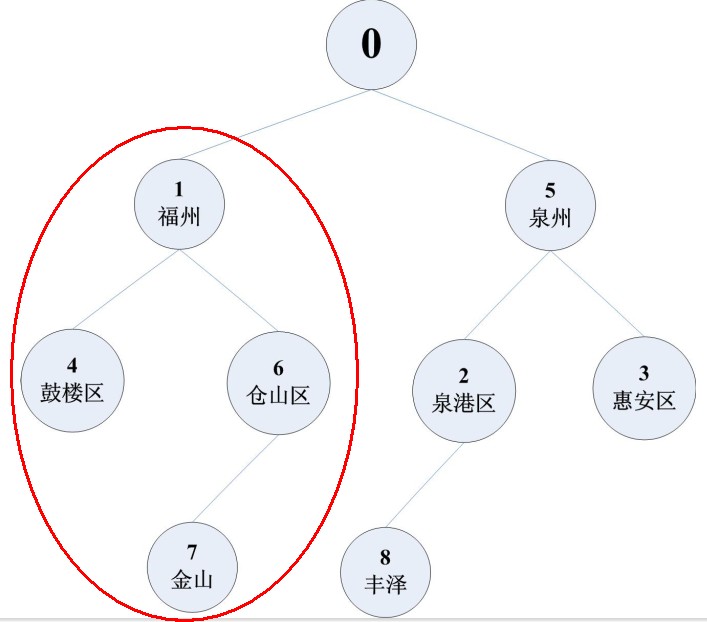
因此想要查询某些信息,只要抓住根结点的条件就可以。。Over~~
Java深克隆(序列化方式)
对于Java的克隆技术,标准的方式是:首先实现Cloneable接口,然后重写clone方法,调用父类clone进行克隆。
介绍另外一种方法,该方法的原理:
利用流将序列化的对象写在流里,因为写在流里面的对象就是原对象的一份拷贝,而原对象还在Java虚拟机里(JVM)里,再从流里面读取出来得到的对象就是得到一份克隆对象。
注意:需要克隆的对象必须实现Serializable接口
接着之前的场景,看下面的例子:
public class User implements Serializable{
private static final long serialVersionUID = 1L;
private String userName;
private Address address;
public User(String userName) {
super();
this.userName = userName;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public Address getAddress() {
return address;
}
public void setAddress(Address address) {
this.address = address;
}
public Object copy() throws IOException, ClassNotFoundException{
//将对象序列化后写在流里,因为写在流里面的对象是一份拷贝,
//原对象仍然在JVM里
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(
bos.toByteArray()));
return ois.readObject();
}
}
public class Address implements Serializable{
private static final long serialVersionUID = 1L;
private String addressName;
public Address(String addressName) {
super();
this.addressName = addressName;
}
public String getAddressName() {
return addressName;
}
public void setAddressName(String addressName) {
this.addressName = addressName;
}
}
/**
* 测试克隆-深克隆(使用序列化的方式进行深克隆)
* 深克隆不但克隆当前的对象,而且还克隆该对象所引用的对象
* @author CST
*/
public class TestClone {
public static void main(String[] args) throws CloneNotSupportedException, IOException, ClassNotFoundException {
User chen = new User("CST");
chen.setAddress(new Address("福州"));
User liu = (User) chen.copy();
liu.setUserName("LXF");
liu.getAddress().setAddressName("泉州");
System.out.println(chen.getUserName()+"="+chen.getAddress().getAddressName());
}
}
输出结果:CST=福州
效果同实现Cloneable接口方式一样
Java克隆技术
前些天,根据需要,加入了克隆技术,学习了下,总结如下:
Java的对象都是引用,当将一个对象赋值给另外一个对象的时候,也就是说指针(当然,java没有指针的概念)同指向同一块内存地址,这个时如果对一个对象进行修改,也必然会修改另外一个对象的值,这明显不是我们想要的,解决这个问题,可以引入克隆技术,我们可以克隆一个对象出来,使得对克隆出来的对象修改不会改变原始对象的值。
克隆分为:浅克隆和深克隆。
浅克隆是指:浅克隆只是克隆当前的对象,不克隆该对象所应用的对象
深克隆是指:深克隆不但克隆当前的对象,而且还克隆该对象所引用的对象
看具体实例:
(模拟场景:用户对象、地址对象、用户对象拥有地址对象)
一、浅克隆
//克隆必须实现Cloneable,调用父类的clone()方法
public class User implements Cloneable{
private String userName;
private Address address;
public User(String userName) {
super();
this.userName = userName;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public Address getAddress() {
return address;
}
public void setAddress(Address address) {
this.address = address;
}
/*
* 克隆当前对象,得到克隆后的对象
* @see java.lang.Object#clone()
*/
@Override
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
//地址对象
public class Address{
private String addressName;
public Address(String addressName) {
super();
this.addressName = addressName;
}
public String getAddressName() {
return addressName;
}
public void setAddressName(String addressName) {
this.addressName = addressName;
}
}
/**
* 测试克隆-浅克隆
* 浅克隆只是克隆当前的对象,不克隆该对象所应用的对象
* @author CST
*/
public class TestClone {
public static void main(String[] args) throws CloneNotSupportedException {
User chen = new User("CST");
chen.setAddress(new Address("福州"));
User liu = (User) chen.clone();
liu.setUserName("LXF");
liu.getAddress().setAddressName("泉州");
System.out.println(chen.getUserName()+"="+chen.getAddress().getAddressName());
}
}
输出结果:CST=泉州
可以看到,虽然User对象可以单独操作,但是视图去修改User下的Address值,仍然是改变了原始用户下的Address值
二、深克隆:
public class User implements Cloneable{
private String userName;
private Address address;
public User(String userName) {
super();
this.userName = userName;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public Address getAddress() {
return address;
}
public void setAddress(Address address) {
this.address = address;
}
//克隆
@Override
public Object clone() throws CloneNotSupportedException {
//克隆对象的同时,也克隆user下的应用对象Address
User user = (User) super.clone();
Address address = (Address) user.getAddress().clone();
user.setAddress(address);
return user;
}
}
public class Address implements Cloneable{
private String addressName;
public Address(String addressName) {
super();
this.addressName = addressName;
}
public String getAddressName() {
return addressName;
}
public void setAddressName(String addressName) {
this.addressName = addressName;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
测试类同上,
输出结果:CST=长乐
这样,才是我们想要的结果。无论修改当前对象还是当前对象所包含的对象,都是两个独立的操作,互不影响。
No Hibernate Session bound to thread,and configuration does not allow creation错误解决方案
忽遇如下错误:
org.hibernate.HibernateException: No Hibernate Session bound to thread, and configuration does not allow creation of non-transactional one here
百度得解:
因:将对应操作入事务即可
方法:于Spring配置文件的事务拦截器中加入对应的类即可~
开发简单请假流程DEMO时知识和错误汇总
搞了将近一周,才把这个请假流程给搞定,在这期间遇到的问题N多,其实很感慨的说Struts2的组件超难用的,组件连把布局都加进去了,超郁闷的,不过为了熟悉下struts2还是硬着头皮用了。有涉及到的技术是Struts2+Jbpm4.3.总结下,遇到的问题以及解决方案,以及一些小知识。
①.Struts2部分。
1.Struts2的组件:下拉单选框,存放Value和Name是通过list属性。
list="#{Value1:Name1,Value2:Name2...}"
例如:<struts:select name="identity"
list="#{'personnel':'员工','manager':'经理','boss':'老板'}" />
2.struts.xml配置中,action结点下的result配置,如果result是指向另外一个Action,需指定属性
type="redirectAction"
例如:
<result name="manager" type="redirectAction">/showTask.action</result>
3.Struts2中的request和response以及Session获取方式:
private ActionContext context = ActionContext.getContext(); //获取Request private HttpServletRequest request = (HttpServletRequest) context.get(ServletActionContext.HTTP_REQUEST); //获取Response private HttpServletResponse response = (HttpServletResponse) context.get(ServletActionContext.HTTP_RESPONSE); //获取Session private Map<String,Object> session = context.getSession();
4.表单的属性名会通过set方法传入到action中的属性名中,而action处理的结果通过相应的get方法来传入到页面上。就不用像以前Struts1那样通过ActionForm来传递了
5.struts2的标签获取session中的值,
如:<struts:property value="#session.loginUser.name"/>
6.访问出错:No result defined for action XXX and result success
解决方法:在package结点添加属性 namespace="/"
7.在jsp页面上用流的方式输出图片,出现
getOutputStream() has already been called for this response异常
解决方法:
在流输出后加入以下两行代码:
out.clear();
out = pageContext.pushBody();
②.Spring (做其他DEMO单元测试时问题)
1.org.springframework.orm.hibernate3.HibernateSystemException: Unknown entity
原因:在配置文件中没有找到对于的PO对象,加入类似于如下代码即可:
<!-- 我记得以前指定名字叫packagesToScan就可的,现在要指定annotatedClasses --> <property name="annotatedClasses"> <list> <value>com.shine.jpbm4.po.WfBusiness</value> <value>com.shine.jpbm4.po.WfStep</value> <value>com.shine.jpbm4.po.WorkflowBusiInfo</value> </list> </property>
2.使用Spring的bean属性拷贝工具类,不允许名字一样,而类型却不一样。
③.Jbpm4.3 部分
1.用TaskService进行completeTask(taskId,variables)时出现
No unnamed transitions were found for the task for 'XXX'错误.
原因:在JPDL文件定义中,每个transition都有指定对应的名字,如果指定了名字,在进行completeTask时必须指定transtion名字,其实也不 一定是transtion的名字,还有可能是其他类型结点的名字,我们统称为outCome
解决方法:使用completeTask(taskId,outCome,vauables)方式进行提交任务。
2.对上面的补充,可通过TaskService获取指定taskId的所有outComes
方法:taskService.getOutcomes(taskId);
3.org.hibernate.HibernateException: instance not of expected entity type
原因进行变量的传输的时候,实体要序列化,实体内部包含的实体也都必须序列化,即实现Serializable接口
4.Jbpm乱码问题:
当提交的表单POST方式提交的时候,遇到的乱码问题,因为JPDL.XML文件指定的是UTF-8编码,但是Tomcat处理提交数据默认是使用ISO-8859-1,因此需要设置提交requet的编码,以前都使用过滤器进行的,为了简单起见,直接指定request为UTF-8编码格式,request.setCharacterEncoding("UTF-8")