收集:Hibernate配置参数和说明
网上收到的一个关于Hibernate的配置参数问题,前几天遇到日志参数设置问题,搜索出来的东西,挺好的,收集了~~~
| 表一:Hibernate 参数配置 | |
| 参数 | 用途 |
| hibernate.dialect | 一个Hibernate Dialect类名允许Hibernate针对特定的关系数据库生成优化的SQL. 取值 full.classname.of.Dialect |
| hibernate.show_sql | 输出所有SQL语句到控制台. 有一个另外的选择是把org.hibernate.SQL这个log category设为debug。 eg. true | false |
| hibernate.format_sql | 在log和console中打印出更漂亮的SQL。 取值 true | false |
| hibernate.default_schema | 在生成的SQL中, 将给定的schema/tablespace附加于非全限定名的表名上. 取值 SCHEMA_NAME |
| hibernate.default_catalog | 在生成的SQL中, 将给定的catalog附加于非全限定名的表名上. 取值 CATALOG_NAME |
|
hibernate.session_ factory_name |
SessionFactory创建后,将自动使用这个名字绑定到JNDI中. 取值 jndi/composite/name |
|
hibernate. max_fetch_depth |
为单向关联(一对一, 多对一)的外连接抓取(outer join fetch)树设置最大深度. 值为0意味着将关闭默认的外连接抓取. 取值 建议在0到3之间取值 |
|
hibernate.default_batch _fetch_size |
为Hibernate关联的批量抓取设置默认数量. 取值 建议的取值为4, 8, 和16 |
|
hibernate. default_entity_mode |
为由这个SessionFactory打开的所有Session指定默认的实体表现模式. 取值 dynamic-map, dom4j, pojo |
| hibernate.order_updates | 强制Hibernate按照被更新数据的主键,为SQL更新排序。这么做将减少在高并发系统中事务的死锁。 取值 true | false |
|
hibernate. generate_statistics |
如果开启, Hibernate将收集有助于性能调节的统计数据. 取值 true | false |
|
hibernate. use_identifer_rollback |
如果开启, 在对象被删除时生成的标识属性将被重设为默认值. 取值 true | false |
|
hibernate.use_sql_ comments |
如果开启, Hibernate将在SQL中生成有助于调试的注释信息, 默认值为false. 取值 true | false |
| 表二:Hibernate JDBC和连接属性 | |
| 属性名 | 用途 |
| hibernate.jdbc.fetch_size | 非零值,指定JDBC抓取数量的大小 (调用Statement.setFetchSize()). |
| hibernate.jdbc.batch_size | 非零值,允许Hibernate使用JDBC2的批量更新. 取值 建议取5到30之间的值 |
|
hibernate.jdbc. batch_versioned_data |
如果你想让你的JDBC驱动从executeBatch()返回正确的行计数 , 那么将此属性设为true(开启这个选项通常是安全的). 同时,Hibernate将为自动版本化的数据使用批量DML. 默认值为false. eg. true | false |
|
hibernate.jdbc. factory_class |
选择一个自定义的Batcher. 多数应用程序不需要这个配置属性. eg. classname.of.Batcher |
|
hibernate.jdbc. use_scrollable_resultset |
允许Hibernate使用JDBC2的可滚动结果集. 只有在使用用户提供的JDBC连接时,这个选项才是必要的, 否则Hibernate会使用连接的元数据. 取值 true | false |
|
hibernate.jdbc. use_streams_for_binary |
在JDBC读写binary (二进制)或serializable (可序列化) 的类型时使用流(stream)(系统级属性). 取值 true | false |
|
hibernate.jdbc. use_get_generated_keys |
在数据插入数据库之后,允许使用JDBC3 PreparedStatement.getGeneratedKeys() 来获取数据库生成的key(键)。需要JDBC3+驱动和JRE1.4+, 如果你的数据库驱动在使用Hibernate的标 识生成器时遇到问题,请将此值设为false. 默认情况下将使用连接的元数据来判定驱动的能力. 取值 true|false |
|
hibernate.connection. provider_class |
自定义ConnectionProvider的类名, 此类用来向Hibernate提供JDBC连接. 取值 classname.of.ConnectionProvider |
|
hibernate.connection. isolation |
设置JDBC事务隔离级别. 查看java.sql.Connection来了解各个值的具体意义, 但请注意多数数据库都不支持所有的隔离级别. 取值 1, 2, 4, 8 |
|
hibernate.connection. autocommit |
允许被缓存的JDBC连接开启自动提交(autocommit) (不建议). 取值 true | false |
|
hibernate.connection. release_mode |
指定Hibernate在何时释放JDBC连接. 默认情况下,直到Session被显式关闭或被断开连接时,才会释放JDBC连接. 对于应用程序服务器的JTA数据源, 你应当使用after_statement, 这样在每次JDBC调用后,都会主动的释放连接. 对于非JTA的连接, 使用after_transaction在每个事务结束时释放连接是合理的. auto将为JTA和CMT事务策略选择after_statement, 为JDBC事务策略选择after_transaction. 取值 on_close | after_transaction | after_statement | auto |
|
hibernate.connection. <propertyName> |
将JDBC属性propertyName传递到DriverManager.getConnection()中去. |
|
hibernate.jndi. <propertyName> |
将属性propertyName传递到JNDI InitialContextFactory中去. |
| 表三:Hibernate缓存属性 | |
| 属性名 | 用途 |
|
hibernate.cache. provider_class |
自定义的CacheProvider的类名. 取值 classname.of.CacheProvider |
|
hibernate.cache. use_minimal_puts |
以频繁的读操作为代价, 优化二级缓存来最小化写操作. 在Hibernate3中,这个设置对的集群缓存非常有用, 对集群缓存的实现而言,默认是开启的. 取值 true|false |
|
hibernate.cache. use_query_cache |
允许查询缓存, 个别查询仍然需要被设置为可缓存的. 取值 true|false |
|
hibernate.cache. use_second_level_cache |
能用来完全禁止使用二级缓存. 对那些在类的映射定义中指定<cache>的类,会默认开启二级缓存. 取值 true|false |
|
hibernate.cache. query_cache_factory |
自定义实现QueryCache接口的类名, 默认为内建的StandardQueryCache. 取值 classname.of.QueryCache |
|
hibernate.cache. region_prefix |
二级缓存区域名的前缀. 取值 prefix |
|
hibernate.cache. use_structured_entries |
强制Hibernate以更人性化的格式将数据存入二级缓存. 取值 true|false |
| 表四:Hibernate事务属性 | |
| 属性名 | 用途 |
|
hibernate.transaction. factory_class |
一个TransactionFactory的类名, 用于Hibernate Transaction API (默认为JDBCTransactionFactory). 取值 classname.of.TransactionFactory |
| jta.UserTransaction | 一个JNDI名字,被JTATransactionFactory用来从应用服务器获取JTA UserTransaction. 取值 jndi/composite/name |
|
hibernate.transaction. manager_lookup_class |
一个TransactionManagerLookup的类名 - 当使用JVM级缓存,或在JTA环境中使用hilo生成器的时候需要该类. 取值 classname.of.TransactionManagerLookup |
|
hibernate.transaction. flush_before_completion |
如果开启, session在事务完成后将被自动清洗(flush)。 现在更好的方法是使用自动session上下文管理。取值 true | false |
|
hibernate.transaction. auto_close_session |
如果开启, session在事务完成后将被自动关闭。 现在更好的方法是使用自动session上下文管理。取值 true | false |
| 表五:Hibernate其他属性 | |
| 属性名 | 用途 |
|
hibernate.current_ session_context_class |
为"当前" Session指定一个(自定义的)策略。eg. jta | thread | custom.Class |
|
hibernate.query. factory_class |
选择HQL解析器的实现. 取值 org.hibernate.hql.ast.ASTQueryTranslatorFactory or org.hibernate.hql.classic.ClassicQueryTranslatorFactory |
|
hibernate.query. substitutions |
将Hibernate查询中的符号映射到SQL查询中的符号 (符号可能是函数名或常量名字). 取值 hqlLiteral=SQL_LITERAL, hqlFunction=SQLFUNC |
| hibernate.hbm2ddl.auto | 在SessionFactory创建时,自动检查数据库结构,或者将数据库schema的DDL导出到数据库. 使用 create-drop时,在显式关闭SessionFactory时,将drop掉数据库schema. 取值 validate | update | create | create-drop |
|
hibernate.cglib. use_reflection_optimizer |
开启CGLIB来替代运行时反射机制(系统级属性). 反射机制有时在除错时比较有用. 注意即使关闭这个优化, Hibernate还是需要CGLIB. 你不能在hibernate.cfg.xml中设置此属性. 取值 true | false |
| 表六:Hibernate SQL 方言 | |
| RDBMS | 方言 |
| DB2 | org.hibernate.dialect.DB2Dialect |
| DB2 AS/400 | org.hibernate.dialect.DB2400Dialect |
| DB2 OS390 | org.hibernate.dialect.DB2390Dialect |
| PostgreSQL | org.hibernate.dialect.PostgreSQLDialect |
| MySQL | org.hibernate.dialect.MySQLDialect |
| MySQL with InnoDB | org.hibernate.dialect.MySQLInnoDBDialect |
| MySQL with MyISAM | org.hibernate.dialect.MySQLMyISAMDialect |
| Oracle (any version) | org.hibernate.dialect.OracleDialect |
| Oracle 9i/10g | org.hibernate.dialect.Oracle9Dialect |
| Sybase | org.hibernate.dialect.SybaseDialect |
| Sybase Anywhere | org.hibernate.dialect.SybaseAnywhereDialect |
| Microsoft SQL Server | org.hibernate.dialect.SQLServerDialect |
| SAP DB | org.hibernate.dialect.SAPDBDialect |
| Informix | org.hibernate.dialect.InformixDialect |
| 表七:Hibernate 日志级别 | |
| 类别 | 功能 |
| org.hibernate.SQL | 在所有SQL DML语句被执行时为它们记录日志 |
| org.hibernate.type | 为所有JDBC参数记录日志 |
|
org.hibernate.tool. hbm2ddl |
在所有SQL DDL语句执行时为它们记录日志 |
| org.hibernate.pretty | 在session清洗(flush)时,为所有与其关联的实体(最多20个)的状态记录日志 |
| org.hibernate.cache | 为所有二级缓存的活动记录日志 |
| org.hibernate.transaction | 为事务相关的活动记录日志 |
| org.hibernate.jdbc | 为所有JDBC资源的获取记录日志 |
| org.hibernate.hql.AST | 在解析查询的时候,记录HQL和SQL的AST分析日志 |
| org.hibernate.secure | 为JAAS认证请求做日志 |
| org.hibernate | 为任何Hibernate相关信息做日志 (信息量较大, 但对查错非常有帮助) |
| 表八:JTA TransactionManagers | |
| Transaction工厂类 | 应用程序服务器 |
|
org.hibernate.transaction. JBossTransaction ManagerLookup |
JBoss |
|
org.hibernate.transaction. WeblogicTransaction ManagerLookup |
Weblogic |
|
org.hibernate.transaction. WebSphereTransaction ManagerLookup |
WebSphere |
|
org.hibernate.transaction. WebSphereExtended JTATransactionLookup |
WebSphere 6 |
|
org.hibernate.transaction. OrionTransaction ManagerLookup |
Orion |
|
org.hibernate.transaction. ResinTransaction ManagerLookup |
Resin |
|
org.hibernate.transaction. JOTMTransaction ManagerLookup |
JOTM |
|
org.hibernate.transaction. JOnASTransaction ManagerLookup |
JOnAS |
|
org.hibernate.transaction. JRun4Transaction ManagerLookup |
JRun4 |
|
org.hibernate.transaction. BESTransaction ManagerLookup |
Borland ES |
学习笔记:证卷基础知识
前两天看了培训的课件~~自己根据课件内容 整理了下整体知识,备忘如下:
证卷模块:
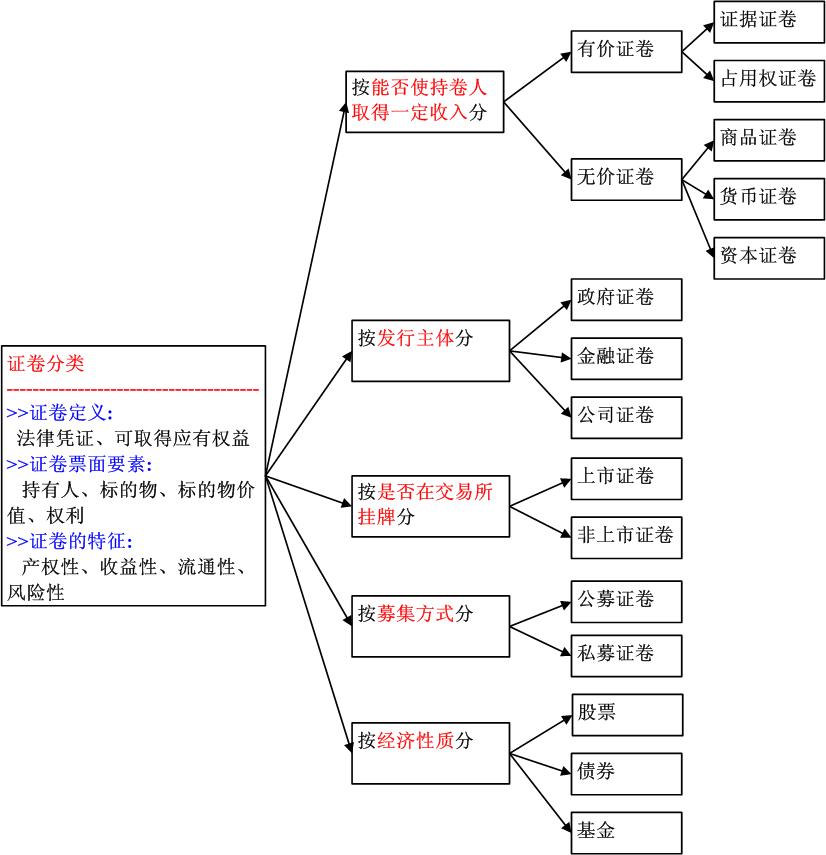
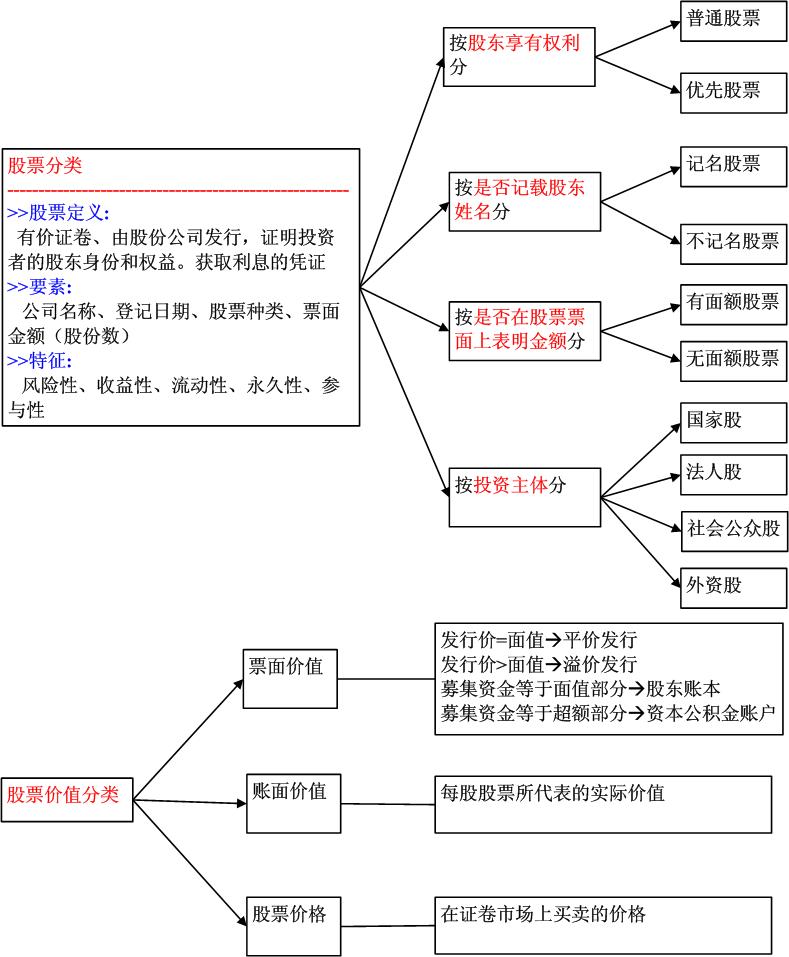
股票模块:
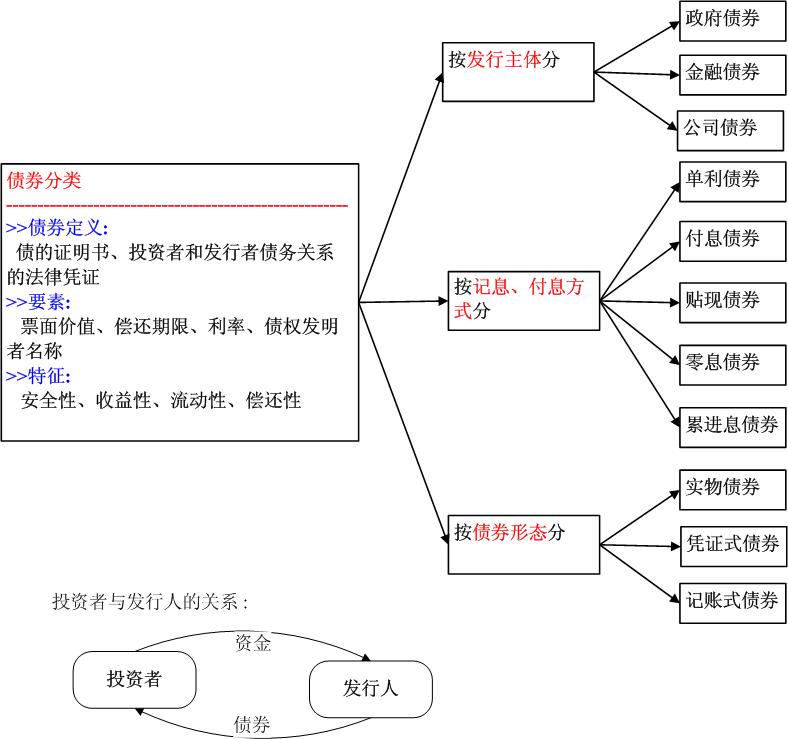
债券模块:
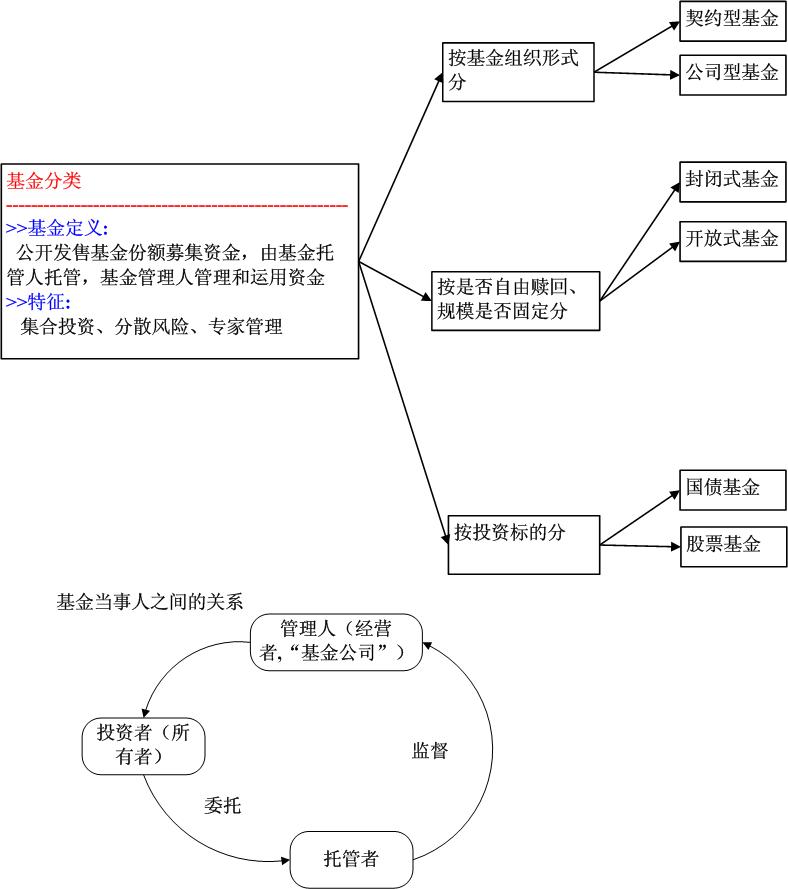
基金模块:
证卷涉及的角色:

出现Unable to find Bean with name XXX 可能原因
今天在公司做项目中,
由Ctrl层 >>> Biz层>>> Dao层 。在Ctrl注入Biz层类 ,在Biz层类注入Dao层类,使用注解的方式进行注入,例如,在Biz层注入Dao层的时候,首先需要将Dao层暴露出来,也就是将这个类标上 @Repository等注解,不然可能会出现Unable to find Bean with name的错误。原理实际上就是定义了一个Bean,没有定义的Bean使用注入自然是找不到这个Bean对象咯~~
换句话说若出现:Unable to find Bean with name 这种错误,不妨看看被注入类是否暴露给其他类咯~~也许是这个问题~
出现org.hibernate.hql.ast.QuerySyntaxException:XX is not mapped.错误可能原因
今天很郁闷的~~这个问题搞了许久,在单元测试一个Dao类的过程,出现如下错误
org.hibernate.hql.ast.QuerySyntaxException: XX is not mapped
XX是一个POJO,按照报错的语句说是,POJO没有被映射,于是,老在POJO上打转,结果是找不到原因。
问了榕哥~~3秒解决问题~原来在spring配置文件中的需要将这个对象的目录引进来,为了调整包结构,更改了目录结构,居然忘记改配置文件中的目录了~~汗~~
用了注解总是容易让人忘记配置啊。~
今天真郁闷~~发表备份下。
Hibernate:出现Not all named parameters have been set错误
初现 Not all named parameters have been set 错误。。
得榕哥帮助~~原来是查询语句参数少设置了~~
顺便悄悄改了同事写的代码~~
另外学到了一招,MyEclipse里面全局查找类快捷键:Ctrl+Shift+R
Windows下查看端口被占用情况
今天开发时遇到的问题~~端口被占用~~想知道哪个程序占用了此端口~~百度了下,虽然后面解决问题是直接重启电脑了。。
但是学习了一招:
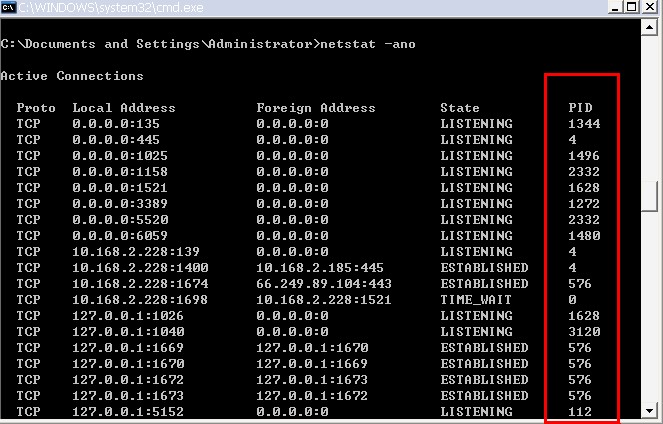
windows下如何查看端口被哪个程序占用了? 按照以下步骤:
1. cmd >> netstat –ano 可以看到使用端口情况。注意对照PID 一栏如图:
2.接着输入 tasklist 可以看到任务运行情况
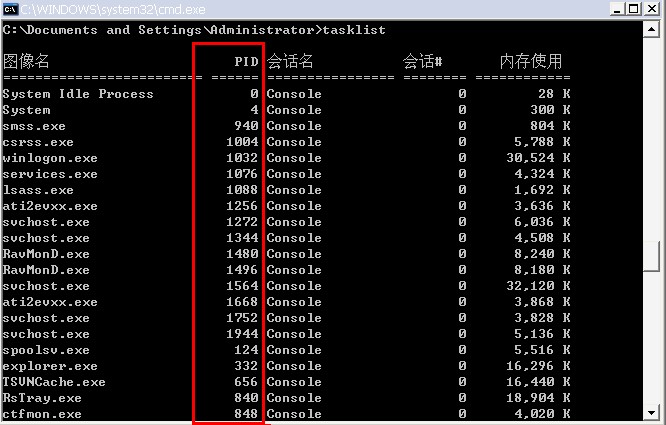
3.请看PID一栏,查看某个端口的使用,记住这个端口所对应的PID,然后在任务列表中通过PID来找到端口被哪个程序所使用,
接下来就可以通过打开任务管理器 来关闭被占用端口所使用的程序,还可以通过以下命令快速关闭任务。
命令如下: taskkill /pid 1040 /t /f 即可。
当然现在有许多防火墙都有此功能~呵~
Spring中ApplicationContextAware接口用法
加载Spring配置文件时,如果Spring配置文件中所定义的Bean类,如果该类实现了ApplicationContextAware接口,那么在加载Spring配置文件时,会自动调用ApplicationContextAware接口中的
public void setApplicationContext(ApplicationContext context) throws BeansException
方法,并且自动可获得ApplicationContext 对象。前提必须在Spring配置文件中指定改类。
一个Demo程序如下:
Spring配置文件中配置:
<bean id="springContext" class="com.shine.spring.SpringContextHelper"></bean>
/**
* ApplicationContext的帮助类
* 自动装载ApplicationContext
*
* @author ChenST
* @create 2010-6-24
*
*/
public class SpringContextHelper implements ApplicationContextAware {
private static ApplicationContext context ;
/*
* 注入ApplicationContext
*/
@Override
public void setApplicationContext(ApplicationContext context)
throws BeansException {
//在加载Spring时自动获得context
SpringContextHelper.context = context;
System.out.println(SpringContextHelper.context);
}
public static Object getBean(String beanName){
return context.getBean(beanName);
}
}
Excel 单元格里换行按"Alt+Enter"
无比囧~~
Excel里换行按“Enter”总是到下一个单元格去~~
原来在单元格里换行是按“Alt+Enter”
使用pdfBox读取PDF文件注意问题
本来想要iText来读取pdf的,结果网上搜索下得出结论,使用iText读取pdf基本上是无法实现的。
于是还是改用了pdfBox来读取文件。于是造成了iText与pdfBox混用的尴尬。
虽然如此,但也遇到了不少问题。下面分析遇到的问题。
---------------------------------------------------------------------------------
1.首先最好要下载pdfbox 1.1的版本。处理文档方面比较完善,如果是低版本的话,是不支持字体与语言的读取。会报错。
2.另外还要下载fontbox 1.1 的包,这对多种字体以及多种语言的支持。注意版本,不然会报有一些类找不到。
3.还要加入common-loggin的包,不然进行读取的时候会遇到类找不到异常,主要是用到org.apache.commons.logging.LogFactory类
---------------------------------------------------------------------------------
遇到的问题主要是使用的包版本太对,或者两者的版本不匹配造成的。
贴个使用pdfbox来读取pdf文档内容的代码:
/**
* 读取指定路径的pdf文件的文本内容<br>
* @param filePath 指定路径
* @return pdf文件的文本内容
* @throws IOException
*/
public String readPdf(String filePath) throws IOException{
File file = new File(filePath);
FileInputStream fis = new FileInputStream(file);
//创建一个PDF解析器
PDFParser parser = new PDFParser(fis);
//进行解析
parser.parse();
//得到PDF文档对象
PDDocument document = parser.getPDDocument();
//新建一个PDF文件剥离器
PDFTextStripper stripper = new PDFTextStripper();
//从文档对象中剥离文本
String content = stripper.getText(document);
fis.close();
document.close();
return content;
Java操作Excel文件之使用JXL 学习笔记
百科上对于JXL的说明:
|
通过java操作excel表格的工具类库
支持Excel 95-2000的所有版本
生成Excel 2000标准格式
支持字体、数字、日期操作
能够修饰单元格属性
支持图像和图表 应该说以上功能已经能够大致满足我们的需要。最关键的是这套API是纯Java的,并不依赖Windows系统,即使运行在Linux下,它同样能够正确的处理Excel文件。另外需要说明的是,这套API对图形和图表的支持很有限,而且仅仅识别PNG格式。 |
前几天学习了下,总结备忘下:贴个关于Excel操作类的代码:(需要加入jxl.jar包)
/**
*
* <pre>
* MS Office Excel 文件操作对象
* 注:利用第三方包jxl.jar进行操作
* 注:暂不支持excel2007版本新格式xlsx后缀名
* 提供操作内容:
* 1.创建Excel文件
* 2.读取Excel文件
* 3.导出(写入)Excel文件
* 4.判断是否为Excel文件
* </pre>
*
* @author 陈书挺
* @create 2010-6-12
* @version v1.0
*
* <pre>
* 修改时间 修改人 修改原因
* 2010-6-12 陈书挺 新建类
* 2010-6-13 陈书挺 修改createExcel(String)方法 | 增加createExcel(String, String...)方法
* </pre>
*
*/
public class ExcelOperator {
/*
* Excel文件后缀名
*/
private static final String EXCEL_POSTFIX = ".xls";
/**
* 创建指定的文件路径的一个Excel文件<br>
* 默认创建3个工作表分别为:Sheet1|Sheet2|Sheet3<br>
* 注:只支持xls格式的文件
* @param filePath 文件路径
* @throws Exception
*/
public void createExcel(String filePath) throws Exception{
this.createExcel(filePath, "Sheet1" , "Sheet2" , "Sheet3");
}
/**
* 创建指定的文件路径的一个Excel文件,并指定工作表名<br>
* 注:只支持xls格式的文件
* @param filePath 文件路径
* @param sheetNames 工作表名数组
* @throws Exception
*/
public void createExcel(String filePath , String...sheetNames) throws Exception{
if(!this.isExcel(filePath)){
throw new Exception("对不起,文件必须是Excel文件,必须是xls格式的文件");
}
File file = new File(filePath);
//工厂方法创建一个可写入的工作薄(WorkBook)
WritableWorkbook workBook = Workbook.createWorkbook(file);
//创建一个可写入的工作表(Sheet) 得到的对象为WritableSheet对象
//工作表名 工作表在工作簿中的位置
for (int i = 0; i < sheetNames.length; i++) {
workBook.createSheet(sheetNames[i], i);
}
workBook.write();
workBook.close();
}
/**
* 读取指定文件路径的Excel文件,以集合方式返回<br>
* 说明:读取所有工作表的内容
* @param filePath 文件路径
* @return List集合,List集合中的元素表示一个工作表
* List中存储String[][]数组,一个数组表示存储工作表的内容
* 返回文件中的所有内容
* @throws Exception
*/
public List<String [][]> readExcel(String filePath) throws Exception{
if(!this.isExcel(filePath)){
throw new Exception("对不起,文件必须是Excel文件,必须是xls格式的文件");
}
List<String [][]> contents = new ArrayList<String[][]>();
File file = new File(filePath);
//创建工作薄
Workbook workBook = Workbook.getWorkbook(file);
//获取工作表
Sheet [] sheets = workBook.getSheets();
if(sheets!=null && sheets.length>0){
for (int i = 0; i < sheets.length; i++) {
String[][] content = this.readExcel(filePath, i);
contents.add(content);
}
}
workBook.close();
return contents;
}
/**
* 将指定内容写入指定的Excel文件,并指定相应的工作表名
* @param filePath 文件路径
* @param contents 数据内容
* @param sheetName 工作表名
* @throws Exception
*/
public void writeExcel(String filePath , String [][] contents ,String sheetName) throws Exception{
if(!this.isExcel(filePath)){
throw new Exception("对不起,文件必须是Excel文件,必须是xls格式的文件");
}
File file = new File(filePath);
//工厂方法创建一个可写入的工作薄(WorkBook)
WritableWorkbook workBook = Workbook.createWorkbook(file);
WritableSheet sheet = workBook.createSheet(sheetName, 0);
for (int i = 0; i < contents.length; i++) {
for (int j = 0; j < contents[i].length; j++) {
sheet.addCell(new Label(j,i,contents[i][j]));
}
}
workBook.write();
workBook.close();
}
/**
* 将指定内容写入指定的Excel文件,并指定相应的工作表名
* @param filePath 文件路径
* @param contents 数据内容
* @param sheetName 工作表名
* @throws Exception
*/
public void writeExcel(String filePath , Vector<Vector<String>> contents , String sheetName) throws Exception{
this.writeExcel(filePath, StringUtils.toStringArray(contents), sheetName);
}
/**
* 读取指定文件路径、指定工作表索引的Excel文件
*
* @param filePath Excel文件路径
* @param sheetIndex 工作表索引 从0开始
* @return 与Excel结构相似的二维数组,二维数组中存储的是表格中的内容
* @throws Exception
*/
public String [][] readExcel(String filePath , int sheetIndex) throws Exception{
if(!this.isExcel(filePath)){
throw new Exception("文件必须是Excel文件,必须是xls格式的文件");
}
File file = new File(filePath);
//创建工作薄
Workbook workBook = Workbook.getWorkbook(file);
//获取工作表
Sheet [] sheets = workBook.getSheets();
if(sheetIndex>sheets.length-1){
throw new Exception("工作表索引["+sheetIndex+"]超出范围");
}
//获取指定工作表
Sheet sheet = sheets[sheetIndex];
//获取当前工作薄的行数
int rows = sheet.getRows();
//获取当前工作薄的列数
int columns = sheet.getColumns();
//存储Excel中的数据
String [][] content = new String[rows][columns];
this.initArrays(content);
for (int i = 0; i < rows; i++) {
//得到当前行的所有单元格
Cell [] cells = sheet.getRow(i);
if(cells!=null && cells.length>0){
for (int j= 0; j < cells.length; j++) {
String cellContent = cells[j].getContents();
content[i][j]=cellContent;
}
}
}
workBook.close();
return content;
}
/**
* 判断指定文件的路径是否是Excel文件
* @param filePath 文件的路径
* @return 是否是Excel文件
* true:是Excel文件
* false:不是Excel文件
*/
public boolean isExcel(String filePath){
//获取文件后缀名
String postfix = FileUtils.getPostfix(filePath);
if(!postfix.equals(ExcelOperator.EXCEL_POSTFIX)){
return false;
}
return true;
}
/*
* 初始化二维数组内容为""
* @param arrays 要初始化二维数组
*/
private void initArrays(String [][] arrays){
for (int i = 0; i < arrays.length; i++) {
for (int j = 0; j < arrays[i].length; j++) {
arrays[i][j]="";
}
}
}
}